How to Use Production Data Securely in Software Development
In a perfect world, engineers wouldn’t need to use production data — information essential for day-to-day business operations — in their development process. Alas, this is not a perfect world.
Unfortunately, many engineering-lead organizations act as if this utopian world exists. Instead of building common-sense policies or tools to facilitate responsible utilization of production data, they ignore the numerous valid use-cases that drive this need.
The result? Engineers eager to do their job devise shadow processes to download production data to their devices. These shadow processes are optimized for the engineer’s immediate need and often don’t consider the security or legal consequences of accessing, copying, and storing production data.
Organizations can be blissfully unaware of these shadow processes for years, but these bad habits will eventually catch up with them. A benign event like an engineer leaving their work laptop in the back of a taxi suddenly becomes a nightmare when IT realizes that the device is unencrypted and contains a recent copy of the production customer database. Instead of a policy gap, you have a headline.
But it doesn’t need to be this way. First, you need to acknowledge and understand what drives this need for production data. You can then snap out of this black and white approach to production data and ask, how can you give your team what they need without putting sensitive information at risk?
Why Can’t Engineers Just Use Synthetic Test Data?
Synthetic test data (or dummy data) often can’t represent every scenario and address edge cases in the real-world environment. The lack of realistic test data can cause production problems and lead to inaccurate or irrelevant results.
Moreover, test data provisioning can become a bottleneck that can threaten the efficiencies gained through automated testing and QA technologies. The delays can impact the implementation of continuous integration and delivery.
On the other hand, using production data for testing is often faster and less expensive. It also provides the legitimacy, validity, complexity, statistical distribution, and timeliness needed for robust testing.
Why Do Engineers Want Production Data On Their Device?
Now that we’ve established why production data is so valuable, you may wonder why engineers often feel the need to transfer it to their device instead of interacting with it over a network?
In many cases, engineers don’t need access to data on their company laptops but are often in a situation where it’s the only way they can interact with it.
For example, an engineer building a new feature may want to know how many people used the old one so they can decide if they should spend a week writing a data migration script. Suppose the only way to find out is to submit a ticket to an overworked SRE team and wait weeks for an answer. In that case, they’d be motivated to get a copy of the entire production database to bypass this incredibly inefficient feedback cycle.
If that same engineer has access to auditable tools to query the production database or run code in a production code console, the need to have data locally diminishes significantly. For example, features like Heroku Dataclips allow engineers to query production data and share valuable queries with other team members.
But even with these self-service tools, you can’t eliminate the demand for on-device access to production data. When engineers have to solve hard-to-diagnose performance issues or hard-to-reproduce bugs, accessing data locally is often the only way to get the near instant-feedback loop they need to diagnose elusive problems.
How to Use Production Data Safely in Software Development
The good news is that you can reap the benefits of using production data in the software development process without compromising data security. Here’s what to do:
Implement a data security policy
If you haven’t already, define a policy to guide how employees use production data internally. It should address duplicating production data onto a work computer and indicate how long it can be kept on the device.
Identify data required for testing
To minimize risks and exposure, you should identify which data is needed for testing and copy only the relevant information to the development environment. Select datasets that can add value to simulating real-life use cases in the production environment.
Remove sensitive and personal identifiable information
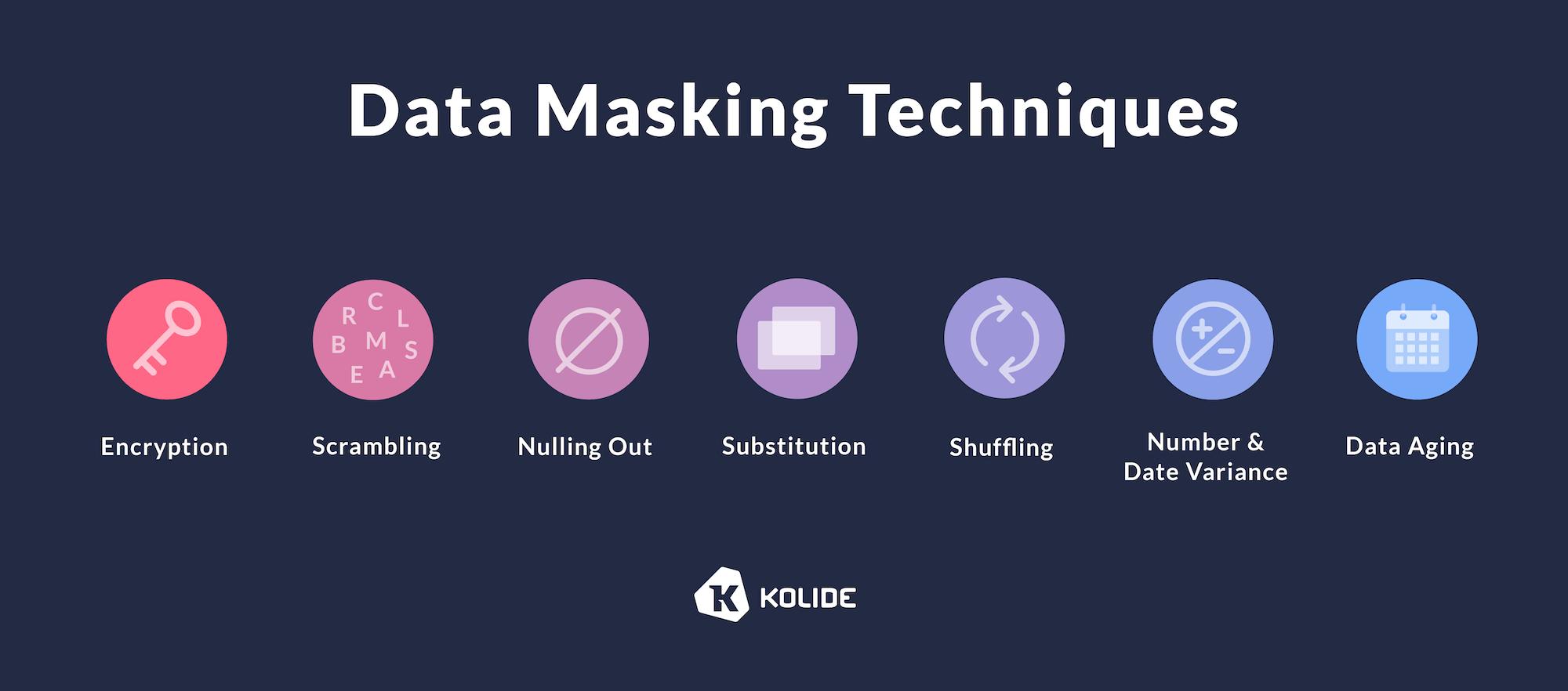
Before copying production data to the development environment, check if the data contains PII or other sensitive business information (e.g., financial data, trade secrets.) Protect it with data masking and obfuscation techniques to make it non-identifiable. These include substitution, shuffling, blurring, pseudonymization, and anonymization.
Ideally, engineering teams can invest time to develop a programmatic understanding of what data is sensitive and devise an automated process to mask it when they need access. Doing this work upfront can pay significant dividends later as businesses that plan to expand into the EMEA must address data governance-related engineering requirements.
Invest in tools for auditable and per-use access to production data
You can reduce the need for on-device production data storage by having the engineering team run and host tools that promote responsible and auditable access via the network.
For example, the SaaS company Basecamp created their own production data console designed to give engineers hands-on keyboard access to production. The activities are fully auditable, allowing the company to protect the most sensitive customer data.
Your Data Security Policy is Only As Good As Its Implementation
Now you have a data security policy to protect your sensitive information. But these measures are only as effective as how well your team is following the guidelines.
How can you ensure that no sensitive information is inadvertently copied to a device or stored beyond the permitted time limit? How can you be sure that the devices engineers use to access the production data are secure at all times?
The process of having IT scan endpoint devices and track down every user to delete sensitive files is riddled with delays and oversights, giving threat actors a window of opportunity to steal valuable data. Meanwhile, locking users out of critical files until the issues are resolved could hold up the development workflow.
You need an effective endpoint security solution that can automatically detect sensitive files remotely and alert users so they can take remediation action.

With Kolide, you can define your data security policy and ensure that all the devices connected to your network adhere to the guidelines. You can also monitor the activities on these devices to ensure that they aren’t accessed by unauthorized personnel.
You can automate scanning and notifications so team members will get an alert if they’re improperly using or storing sensitive data. The messages also offer self-remediation steps they can take right away to resolve the issue.
Kolide helps ensure that every employee does their part in keeping sensitive information safe without resorting to rigid management. By learning at the point of performance, you can help employees turn your privacy policy into action — understanding their roles in keeping your data safe while doing their jobs.
If you’d like to read more tutorial content like this, sign up for our biweekly newsletter.