How to Read Nested Complex Plists in Osquery
Pivoting SQL data with MAX & CASE

Why Can’t These Rows Be Columns?
If you have ever queried the registry or plist tables in osquery, you have
encountered results that were formatted unlike any other osquery data.
Whereas osquery generally utilizes a relational data model for its table
schema, results from plist & registry more closely resemble the
entity–attribute–value (EAV) data model.
Let’s examine the basic structural differences between the two:
The relational data model
Organizes data into columns:
The columnar output allows us to know ahead of time what data to expect. Our predefined schema below, indicates that every person record can have both a first and a last name:
SELECT * FROM people;
+---------+------------+-----------+
| user_id | first_name | last_name |
+---------+------------+-----------+
| 1 | Jane | Lewis |
| 2 | John | Smith |
+---------+------------+-----------+
The EAV data model
Organizes data into rows:
In our case the structure maps the following way:
Entity — user_id
Attribute — key
Value — value
While all of the data from the first table is present, there is also an entry
for eye_color belonging to user_id:2. This attribute would necessitate its
own column in the relational model.
SELECT * FROM people;
+---------+------------+-------+
| user_id | key | value |
+---------+------------+-------+
| 1 | first_name | Jane |
| 1 | last_name | Lewis |
| 2 | first_name | John |
| 2 | last_name | Smith |
| 2 | eye_color | blue | ←←
+---------+------------+-------+
Which data model is better?
Each data model possesses its own advantages and drawbacks. Typically, a
relational model is best suited for scenarios where there will be a rigid
schema and where relational operations such as JOIN‘s will be necessary.
The EAV model on the other hand is more dynamic because new attributes (columns in the relational model) can be added without modifying the underlying schema.
The bulk of osquery’s interactions are within the context of a relational model.
Each table has its own unique columns which can be used to easily
compartmentalize data and JOIN it with other data when necessary.
But sometimes…
As we mentioned above, you will sometimes run into data that doesn’t adhere to
the relational model. Several of the data-sources available in osquery return
results formatted in the EAV model, the two most important being the plist
table for macOS devices and the registry table for Windows devices.
What does this mean for an osquery user?
When querying devices for several values that are stored in a single registry
directory, they will receive a separate row for every key/value pair. Let’s
take a look at the following example:
SELECT name, type, data
FROM registry
WHERE key =
"HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\"
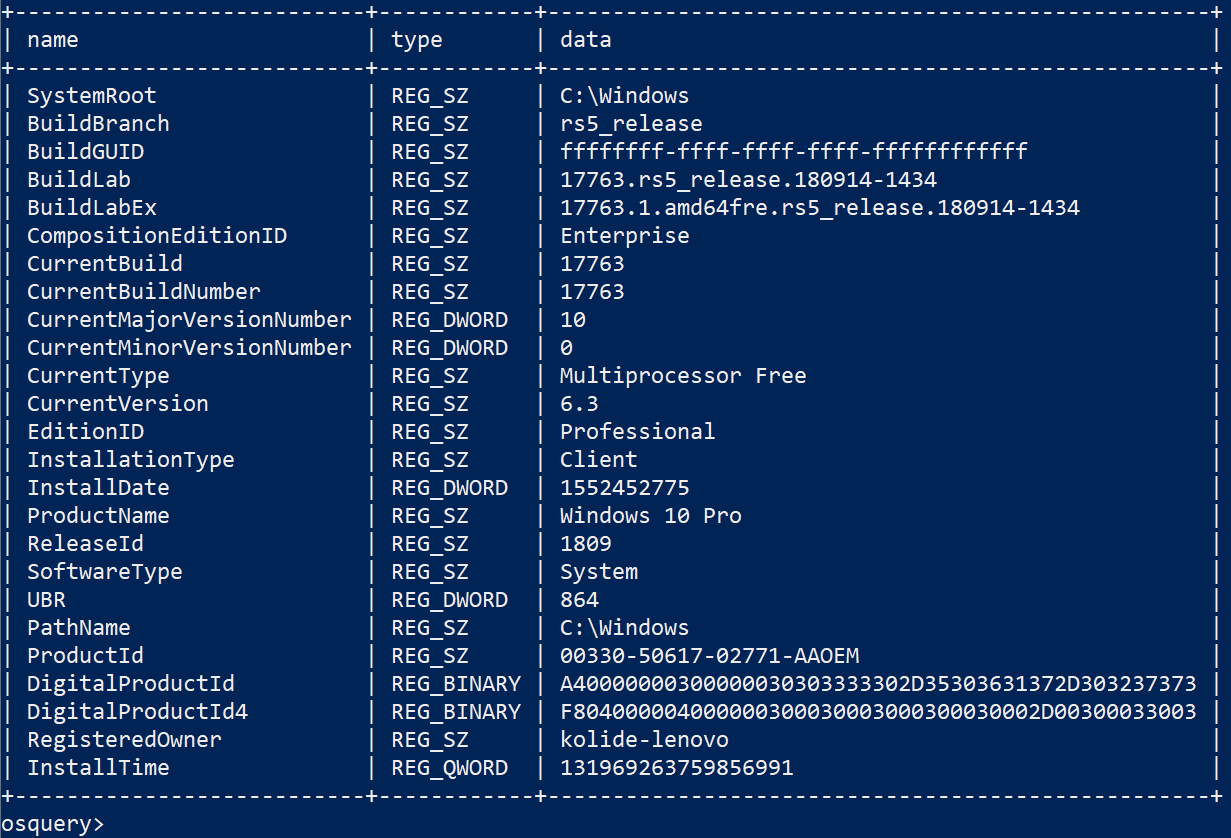
As we can see there is a large degree of operating system info available via the
registry. When we compare this with the the output of the corresponding osquery
virtual table os_version we can quickly observe the difference in structure
between the two datasets:
SELECT * FROM os_version;
Compared to the registry output, the os_version does not mention the
release or build_revision number among other useful OS information. Leveraging
the registry can be critical for closing some of the gaps in the existing Windows
virtual table output. Unfortunately, the registry data is hideous to look at
and virtually unusable when you want to JOIN against another table.
EAV formatting issues likewise affect the output of the osquery plist table.
Let’s take a look at the com.apple.loginwindow.plist. Which caches among other
things whether the Guest Account is enabled on a macOS device.
SELECT
key,
value
FROM plist
WHERE path = '/Library/Preferences/com.apple.loginwindow.plist';
+----------------------------+----------------------------+
| key | value |
+----------------------------+----------------------------+
| GuestEnabled | 0 |
| OptimizerLastRunForSystem | 168755200 |
| lastUserName | fritz-imac |
| UseVoiceOverLegacyMigrated | 1 |
| OptimizerLastRunForBuild | 39865152 |
| LoginwindowText | Fritz, I found some cake |
| lastUser | loggedIn |
+----------------------------+----------------------------+
The output of this plist is more manageable than the earlier registry example.
However, when querying large numbers of devices it can be preferable to produce
a single row per device by pivoting each key/value pair into its own respective
column.
The most significant advantage of pivoting, is that unless our data is stored
in a columnar format, it is terrifically burdensome to JOIN it against another
osquery datasource. There are a large number of plists that belong to only a
single user and the ability to JOIN against the users table is invaluable.
So how do we get these disorganized rows into a neat and tidy columns?
Pivoting Data Using MAX and CASE
Thankfully, there is a workaround to handling this mismatch of data structure.
Although SQLite does not support the PIVOT function of more recent SQL
technologies, CASE can be utilized as a pseudo-pivot so long as an aggregation
function is also present. The aggregation function serves to enforce a single
returned row of data. Let’s work stepwise through our above
com.apple.loginwindow.plist example to arrive at columnar output:
Level 1 Transformations: CASE
CASE works as the IF/THEN logic of SQLite, the standard format is as follows:
-
CASE— begin if/then argument -
WHEN— If statement -
THEN— Then statement -
ELSE— optional (otherwise defaults to NULL) -
END AS— column name of outputted value
You can use all typical SQL logic within the WHEN/THEN/ELSE statements,
including sub-selects, size comparisons, etc. For our purposes we want to output
a corresponding value for a specific key as a column.
To pivot this data into a column, you might be thinking we could simply alias our output and call it a day:
SELECT
value AS guest_enabled
FROM plist
WHERE path = '/Library/Preferences/com.apple.loginwindow.plist'
AND key = 'GuestEnabled';
+---------------+
| guest_enabled |
+---------------+
| 0 |
+---------------+
Unfortunately, this approach fails when dealing with more than one value.
With CASE however, we can pivot multiple values at the same time. If we take
our example of the com.apple.loginwindow.plist. We can see the data as
individual columns:
SELECT
CASE WHEN key = 'GuestEnabled'
THEN value END AS guest_enabled,
CASE WHEN key = 'OptimizerLastRunForSystem'
THEN value END AS optimizer_last_run,
CASE WHEN key = 'lastUserName'
THEN value END AS last_login_user,
CASE WHEN key = 'UseVoiceOverLegacyMigrated'
THEN value END AS legacy_voice_over,
CASE WHEN key = 'OptimizerLastRunForBuild'
THEN value END AS optimizer_build,
CASE WHEN key = 'LoginwindowText'
THEN value END AS login_window_message,
CASE WHEN key = 'lastUser'
THEN value END AS last_user
FROM plist
WHERE path = '/Library/Preferences/com.apple.loginwindow.plist';

Yuck, not quite what we want. All of our columns look right but our rows are a
staggered mess and the data is not together in a usable format. CASE has run
through each possible row and stopped when it hit a match. You can visualize
this below:

So how do we flatten this output?
Level 2 transformations: MAX(CASE
Pivoting single rows of data into columns
The MAX function returns only the highest value in a returned result-set:
WITH
example_table(number_value) AS (
VALUES
(1024),
(435),
(3),
(10928),
(512)
)
SELECT MAX(number_value) FROM example_table;
+-------------------+
| MAX(number_value) |
+-------------------+
| 10928 |
+-------------------+
Calling the MAX operator will force the CASE function to run through all
possible matches and return the highest result (ignoring NULL’s) instead of
only the first result. We can take advantage of that behavior to smush our
results together like the graphic below:

To properly format our query, we will wrap our existing CASE statement in a MAX(...) function:
SELECT
MAX(CASE WHEN key = 'GuestEnabled'
THEN value END) AS guest_enabled,
MAX(CASE WHEN key = 'OptimizerLastRunForSystem'
THEN value END) AS optimizer_last_run,
MAX(CASE WHEN key = 'lastUserName'
THEN value END) AS last_login_user,
MAX(CASE WHEN key = 'UseVoiceOverLegacyMigrated'
THEN value END) AS legacy_voice_over,
MAX(CASE WHEN key = 'OptimizerLastRunForBuild'
THEN value END) AS optimizer_build,
MAX(CASE WHEN key = 'LoginwindowText'
THEN value END) AS login_window_message,
MAX(CASE WHEN key = 'lastUser'
THEN value END) AS last_user
FROM plist WHERE path = '/Library/Preferences/com.apple.loginwindow.plist';

Nice just what we hoped to see!
This works great for our plist because it has only one set of data to pivot but what happens when we have multiple arrays that we would like to reconstruct?
If we use our MAX(CASE approach as it is currently written, we will only ever
return one row of data. Let’s explore how we can avoid that situation by
adding a GROUP BY operator.
Level 3 transformations: MAX(CASE & GROUP BY
Dealing with multiple arrays of data within a single plist:
Like our above example we will use MAX to flatten and CASE to alias the
data, transposing the data arrangement. Let’s try to return all of the iPad,
iPod and iPhone devices associated with a macOS device via the following plist:
~/Library/Preferences/com.apple.iPod.plist
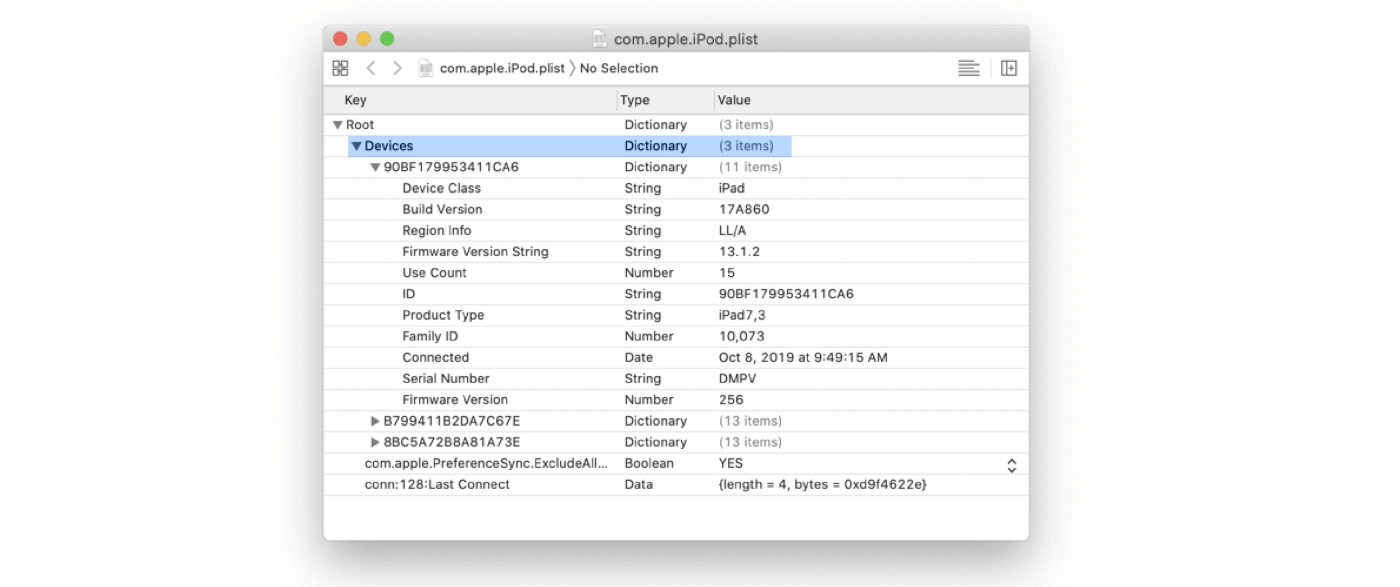
We can see there are three devices cataloged in the above plist each storing their own array of data (Device Class, Build Version, Serial Number, etc.). Let’s output the contents using osquery to understand how that data is stored in a flattened format:
SELECT
subkey,
value
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist';
+------------------------------------------+-------------------+
| subkey | value |
+------------------------------------------+-------------------+
| 90BF179953411CA6/Device Class | iPad |
| 90BF179953411CA6/Build Version | 17A860 |
| 90BF179953411CA6/Region Info | LL/A |
| 90BF179953411CA6/Firmware Version String | 13.1.2 |
| 90BF179953411CA6/Use Count | 15 |
| 90BF179953411CA6/ID | 90BF************ |
| 90BF179953411CA6/Product Type | iPad7,3 |
| 90BF179953411CA6/Family ID | 10073 |
| 90BF179953411CA6/Connected | 1570542555.187774 |
| 90BF179953411CA6/Serial Number | DMPV************ |
| 90BF179953411CA6/Firmware Version | 256 |
| B799411B2DA7C67E/Region Info | LL/A |
| B799411B2DA7C67E/Device Class | iPhone |
| B799411B2DA7C67E/IMEI | 3554************ |
| B799411B2DA7C67E/ID | B799411B2DA7C67E |
....
We can see that the subkey column contains the identifier of a device along
with an associated attribute: 90BF179953411CA6/Device Class
To keep track of what device a value belongs to, let’s first SPLIT that
subkey out so that we can use it as a unique identifier:
SELECT
subkey,
SPLIT(subkey, '/', 0) AS unique_id
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist';
+------------------------------------------+------------------+
| subkey | unique_id |
+------------------------------------------+------------------+
| 90BF179953411CA6/Device Class | 90BF179953411CA6 |
| 90BF179953411CA6/Build Version | 90BF179953411CA6 |
| 90BF179953411CA6/Region Info | 90BF179953411CA6 |
| 90BF179953411CA6/Firmware Version String | 90BF179953411CA6 |
| 90BF179953411CA6/Use Count | 90BF179953411CA6 |
| 90BF179953411CA6/ID | 90BF179953411CA6 |
| 90BF179953411CA6/Product Type | 90BF179953411CA6 |
| 90BF179953411CA6/Family ID | 90BF179953411CA6 |
| 90BF179953411CA6/Connected | 90BF179953411CA6 |
| 90BF179953411CA6/Serial Number | 90BF179953411CA6 |
| 90BF179953411CA6/Firmware Version | 90BF179953411CA6 |
| B799411B2DA7C67E/Region Info | B799411B2DA7C67E |
| B799411B2DA7C67E/Device Class | B799411B2DA7C67E |
| B799411B2DA7C67E/IMEI | B799411B2DA7C67E |
....
Next let’s condense these unique_id’s and remove duplicate entries with a
GROUP BY operator:
SELECT
subkey,
SPLIT(subkey, '/', 0) AS unique_id
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist'
GROUP BY unique_id;
+-------------------------------+------------------+
| subkey | unique_id |
+-------------------------------+------------------+
| 8BC5A72B8A81A73E/Region Info | 8BC5A72B8A81A73E |
| 90BF179953411CA6/Device Class | 90BF179953411CA6 |
| B799411B2DA7C67E/Region Info | B799411B2DA7C67E |
+-------------------------------+------------------+
We can now use this unique identifier to rebuild and transpose the data using
our CASE function from before. Let’s select a value only when a specific
subkey (“Device Class”) is found:
SELECT
subkey,
SPLIT(subkey, '/', 0) AS unique_id,
CASE WHEN subkey LIKE '%Device Class'
THEN value
END AS device_class
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist'
GROUP BY unique_id;
+-------------------------------+------------------+--------------+
| subkey | unique_id | device_class |
+-------------------------------+------------------+--------------+
| 8BC5A72B8A81A73E/Region Info | 8BC5A72B8A81A73E | |
| 90BF179953411CA6/Device Class | 90BF179953411CA6 | iPad |
| B799411B2DA7C67E/Region Info | B799411B2DA7C67E | |
+-------------------------------+------------------+--------------+
As we can see, this result is not what we would expect, we have only one
result with the desired: subkey LIKE '%Device Class', this is where the magic
of MAX comes in.
As we learned, MAX forces a query to return only the greatest row in a
given result set, importantly for us it also ignores NULL results:
SELECT
subkey,
SPLIT(subkey, '/', 0) AS unique_id,
MAX(CASE WHEN subkey LIKE '%Device Class'
THEN value
END) AS device_class
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist'
GROUP BY unique_id;
+-------------------------------+------------------+--------------+
| subkey | unique_id | device_class |
+-------------------------------+------------------+--------------+
| 8BC5A72B8A81A73E/Device Class | 8BC5A72B8A81A73E | iPhone |
| 90BF179953411CA6/Device Class | 90BF179953411CA6 | iPad |
| B799411B2DA7C67E/Device Class | B799411B2DA7C67E | iPhone |
+-------------------------------+------------------+--------------+
We can continue to expand this same approach to construct an entire table of
attached iDevices by adding additional CASE statements. Let’s take a look at
that below:
SELECT SPLIT(subkey, '/', 0) AS device_id,
MAX(CASE WHEN subkey LIKE '%Device Class'
THEN value
END) AS device_class,
MAX(CASE WHEN subkey LIKE '%Product Type'
THEN value
END) AS product_type,
MAX(CASE WHEN subkey LIKE '%Serial Number'
THEN value
END) AS serial_number,
MAX(CASE WHEN subkey LIKE '%Connected'
THEN datetime(CAST(value as integer), 'unixepoch')
END) AS connected
FROM plist WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist'
AND device_id != ''
GROUP BY device_id;

Woohoo!
You can see that we have been able to take previously messy and flattened data of the plist and pivoted the values from rows into columns, presenting the data in format more typical of osquery’s virtual tables.
Working with the Windows Registry: Faking a GROUP BY
When working with the registry, you may not have a column available to
GROUP BY in order to effectively flatten the data with MAX. If you do not
have to worry about arrays you can deal with that sort of situation by
providing a static column. For example, in the query below (which displays
various Windows Firewall Profile Settings), I use SELECT 'test' AS idx and
then later I GROUP BY idx.
WITH
registry_data AS (
SELECT
SPLIT(key, '\', 7) AS profile,
name,
data,
'test' AS idx
FROM registry r
WHERE r.path IN
('\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\SharedAccess\Parameters\FirewallPolicy\PublicProfile\EnableFirewall',
'\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\SharedAccess\Parameters\FirewallPolicy\StandardProfile\EnableFirewall',
'\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\SharedAccess\Parameters\FirewallPolicy\DomainProfile\EnableFirewall')
),
firewall_profiles AS (
SELECT
MAX(CASE WHEN profile = 'DomainProfile'
THEN data
END) AS domain_profile,
MAX(CASE WHEN profile = 'StandardProfile'
THEN data
END) AS standard_profile,
MAX(CASE WHEN profile = 'PublicProfile'
THEN data
END) AS public_profile
FROM registry_data
GROUP BY idx
)
SELECT * FROM firewall_profiles;
+----------------+------------------+----------------+
| domain_profile | standard_profile | public_profile |
+----------------+------------------+----------------+
| 1 | 1 | 1 |
+----------------+------------------+----------------+
Joining plists against users
Because the iPod.plist belongs to specific users we can join on the users
table if we wanted to see which user account the devices are associated with.
The easiest method to JOIN is using the path of the plist to
reconstruct the directory column of the users table with a SPLIT and ||
(concat).
WITH connected_ipods AS(
SELECT SPLIT(subkey, '/', 0) AS device_id,
MAX(CASE WHEN subkey LIKE '%Device Class'
THEN value
END) AS device_class,
MAX(CASE WHEN subkey LIKE '%Product Type'
THEN value
END) AS product_type,
MAX(CASE WHEN subkey LIKE '%Serial Number'
THEN value
END) AS serial_number,
MAX(CASE WHEN subkey LIKE '%Connected'
THEN datetime(CAST(value as integer), 'unixepoch')
END) AS connected,
'/Users/' || SPLIT(path, '/', 1) AS directory
FROM plist
WHERE path LIKE '/Users/%/Library/Preferences/com.apple.iPod.plist'
AND device_id != ''
GROUP BY device_id)
SELECT
ci.*,
u.username
FROM connected_ipods ci
JOIN users u USING(directory);

Where does the EAV pivot not work?
Unfortunately, without a column that can be used to reliably GROUP BY
(eg. a key that will enforce uniqueness) pivots will not work if there are
duplicate entries or null values.
What does this mean in the context of osquery?
Well for instance, using the approach described above, we cannot reconstruct the Software Update History plist into a more usable relational model:
SELECT
key,
subkey,
value
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist';
+------+----------------+----------------------------------+
| key | subkey | value |
+------+----------------+----------------------------------+
| root | __installState | Installed |
| root | installDate | 1515003293 |
| root | title | iTunes |
| root | version | 12.7.2 |
| root | __installState | Installed |
| root | installDate | 1520005418 |
| root | title | macOS High Sierra 10.13.3 Update |
Because the key value is always root we cannot rely on using it as the
GROUPBY for our MAX function. Likewise, because the subkey column has
duplicate values it also cannot be relied upon to effectively GROUP BY.
If we try either of these approaches we will at best end up with a single update that flattens and overwrites the other matching entries.
However… there is a workaround if you are willing to assume some risk…
Getting Around Lossy Data Flattening with SQLite Hacks (Rowid Increments)
Level 9000+ transformations: MAX(CASE WHEN rowid IN
Dealing with multiple arrays of data within a single plist, without a unique key
This method is an extremely brittle workaround to the above example.
Because osquery returns data from certain tables (plist, registry) in a
semi-predictable order (the files are read out line by line), we can use the
hidden SQLite column rowid to return a row of arbitrary position related to
another specified row.
Take the table below for example, I have bolded productKey and title to show
their position in relation to one another:
SELECT
rowid,
subkey
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist';
+-------+--------------------+
| rowid | subkey |
+-------+--------------------+
| 0 | __isSoftwareUpdate |
| 1 | release-notes |
| 2 | __installState |
| 3 | title | ←--+
| 4 | installDate | |
| 5 | version | |
| 6 | productKey | ←--+ (rowid -3)
| 7 | __isSoftwareUpdate |
| 8 | release-notes |
| 9 | __installState |
| 10 | title |
| 11 | installDate |
| 12 | version |
| 13 | productKey |
Here we can see that each Software Update contains 7 associated keys:
-
__isSoftwareUpdatewhether the update is considered a 'software update’ -
release-notesnotes on update -
__installStatewhether the update has been installed yet -
titlename of update -
installDatedate update was installed -
versionoptional version string -
productKeyunique identifier of update
I have bolded productKey above because of its unique content. In order to
perform the MAX(CASE pivot later on, we will use it as a unique identifier for
our GROUP BY function to link the other associated values.
If we wanted to return the title of a Software Update we can ask osquery to
return the value of the row that is 3 rows above productKey:
SELECT
subkey,
value AS title
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist'
AND rowid IN (
SELECT rowid - 3
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist'
AND subkey = 'productKey'
)
+--------+---------------------------------------------------------+
| subkey | title |
+--------+---------------------------------------------------------+
| title | iTunes |
| title | iTunes |
| title | macOS High Sierra 10.13.3 Update |
| title | macOS High Sierra 10.13.3 Supplemental Update |
| title | Command Line Tools (macOS High Sierra version 10.13) |
| title | iTunes |
| title | Command Line Tools (macOS High Sierra version 10.13) |
| title | macOS High Sierra 10.13.4 Update |
| title | Security Update 2018-001 |
| title | iTunes |
| title | macOS High Sierra 10.13.5 Update |
As we can see this approach could then be extended and combined with the
MAX(CASE strategy outlined above to return each of the corresponding values
of interest by defining their position in relation to another row.
We need to alias the position of each relevant value that we want to pivot
into a column by defining the relative rowid of each.
To simplify this process I find it helpful to compartmentalize my data
collection using temporary tables which we can create using the WITH operator.
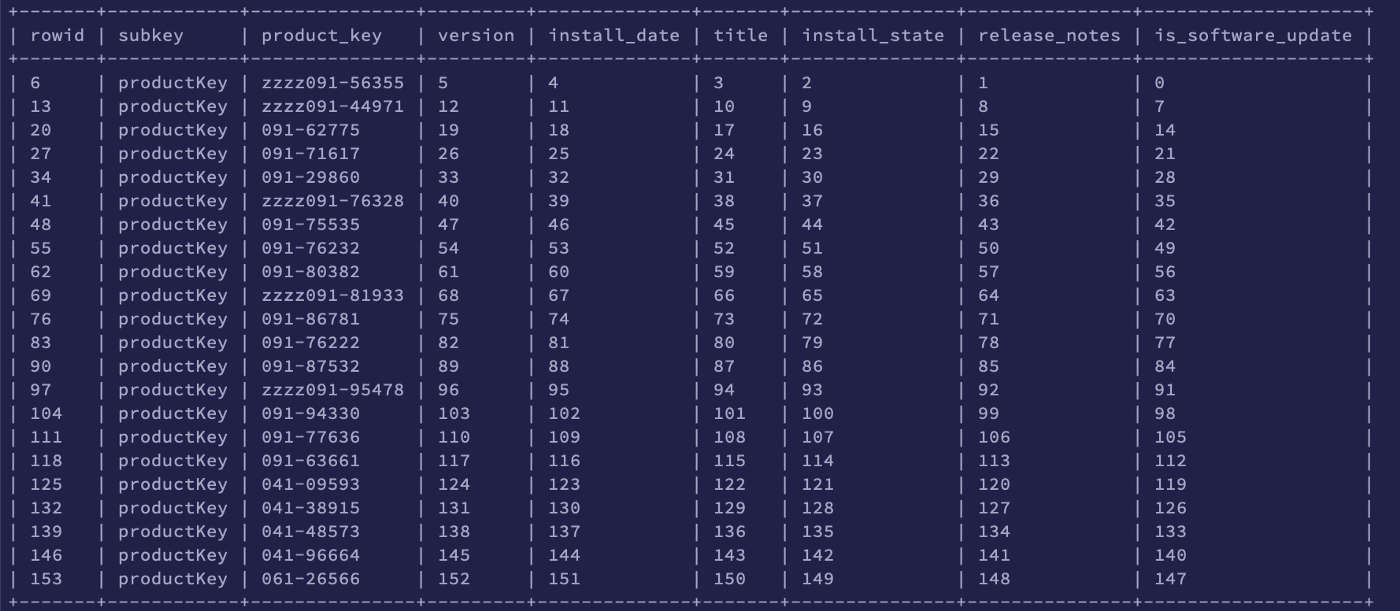
Below, I first output the total data of the Software Update plist to a temp
table I call plist_output. I then create a series of indexes using the rowid
in relation to the position where subkey = 'productKey':
WITH
plist_output AS (
SELECT
rowid,
subkey,
value
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist'
)
SELECT
rowid,
subkey,
value AS product_key,
rowid -1 AS version,
rowid -2 AS install_date,
rowid -3 AS title,
rowid -4 AS install_state,
rowid -5 AS release_notes,
rowid -6 AS is_software_update
FROM plist_output
WHERE subkey = 'productKey'
We can then further alias this index record into another temporary table I will
call unique_identifier. We can now use these indexes and the
MAX(CASE function GROUP BY‘ed on the new product_key column to get our
desired final output:
WITH
plist_output AS (
SELECT
rowid,
subkey,
value
FROM plist
WHERE path = '/private/var/db/softwareupdate/journal.plist'
),
unique_identifier AS (
SELECT
rowid,
subkey,
value AS product_key,
rowid -1 AS version,
rowid -2 AS install_date,
rowid -3 AS title,
rowid -4 AS install_state,
rowid -5 AS release_notes,
rowid -6 AS is_software_update
FROM plist_output
WHERE subkey = 'productKey'
),
software_updates AS (
SELECT
MAX (ui.rowid) AS rowid,
MAX (product_key) AS product_key,
MAX (CASE WHEN po.rowid IN (title)
THEN po.value
END) AS title,
MAX (CASE WHEN po.rowid IN (install_date)
THEN po.value
END) AS install_date,
MAX (CASE WHEN po.rowid IN (version)
THEN po.value
END) AS version,
MAX (CASE WHEN po.rowid IN (install_state)
THEN po.value
END) AS install_state,
MAX (CASE WHEN po.rowid IN (is_software_update)
THEN po.value
END) AS is_software_update,
MAX (CASE WHEN po.rowid IN (release_notes)
THEN po.value
END) AS release_notes
FROM unique_identifier ui, plist_output po
GROUP BY product_key
ORDER BY rowid ASC
)
SELECT
product_key,
title,
version,
datetime(install_date, 'unixepoch') AS install_date,
install_state,
is_software_update,
SUBSTR(release_notes, 0, 50) || '...' AS release_notes_truncated
FROM software_updates;
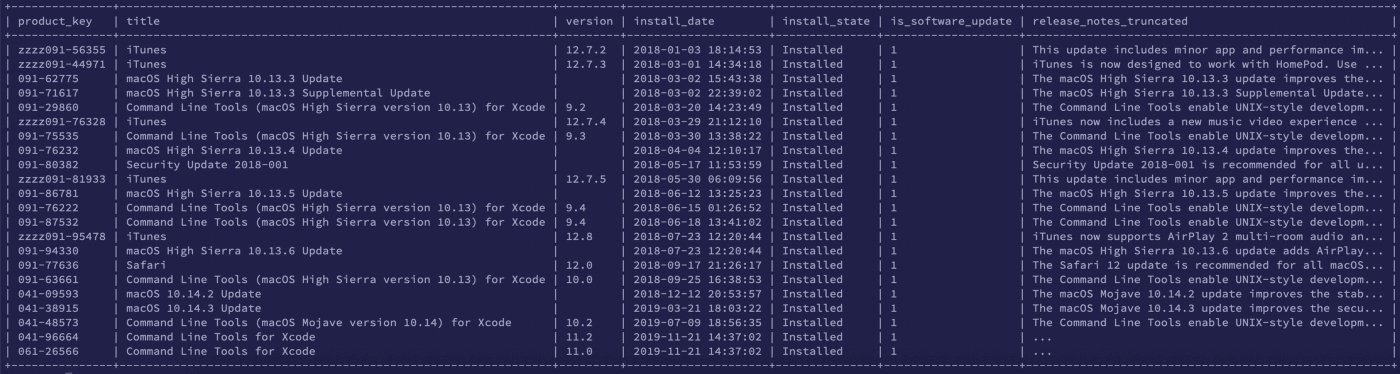
Phew! What a silly thing to do!
While it is encouraging to have this tool in our kit, I cannot stress highly enough that it will cause you embarrassment and frustration if not utilized with careful judgment of data order/uniformity. It will break in more places than it will work.
Wrapping Things Up:
With the techniques described, a combination of (MAX(CASE...)) & GROUP BY
will convert pesky rows into accommodating columns. You now have the tools
to transform and pivot osquery results from the registry and plist tables.
Using these tables you can considerably extend the data collection of osquery beyond what is accessible in the existing virtual tables.
A Pluf For What We Are Doing at Kolide
These techniques have allowed us to construct and extend many of our Inventory tables which beautify the raw osquery output. I wanted to give a peek at some of the strategies we’ve utilized so that others can build great queries.
If you are after beautiful osquery data without the work. I recommend taking a look at our Device Trust announcement. In addition to carefully curated output you can expect to see the following:
- Automatic User to Device Assignment (macOS, Windows and Linux)
- Checks: An alertable framework for device compliance/security
- Interactive Slack App with customizable End-User Notifications
- Live Query (request Beta access today, public launch soon!)
- API (request Beta access today, public launch soon!)
If you’d like to read more osquery content like this, sign up for our biweekly newsletter.