Evergreen Vulnerability Management

Endpoint vulnerability management has always been a valuable yet tough nut to crack. Organizations that successfully implement an effective vulnerability management program benefit in two ways. First, they are compromised less often. Second, if a single device does become compromised, the degree of lateral movement an attacker can enjoy is significantly constrained. That means if an organization is compromised, there would be far fewer negative financial and reputational ramifications.
Given these facts, fast-growing organizations are eager to manage vulnerabilities across servers and user-driven endpoints comprehensively. With the vast proliferation of endpoint agents that can collect the necessary data to run such a program, these benefits have never been more accessible. The question is, how well are organizations faring?
I recently came across a sobering study by the Ponemon Institute about on-premise and cloud vulnerabilities. The following statement leapt off the page…
Fifty-three percent of respondents say their organizations had a data breach in the past two years. […] of these data breaches, 42 percent of respondents say they occurred because a patch was available for a known vulnerability but not applied.
A failure in detection is unfortunate but easy to understand and forgive. As IT administrators and security practitioners, we know it is not possible to enumerate all potential flaws in installed software.
That isn’t the case here. Here, the problems are known in advance and are enumerated on a list of things to be fixed! What we have isn’t a failure in detection, but a failure in the processes we use to respond and remediate. In the case of the organizations studied, these processes are either totally broken or simply do not scale.
The study goes on to enumerate more troubling statistics:

We need to understand the root cause in flawed thinking that results in such poor performance. Luckily, we don’t have to look far as many of these problems are rooted in the fundamental design of the vulnerability program itself.
The Naive Top-Down Approach
When organizations plan their first vulnerability detection and management programs, they tend to approach it by following these steps:
Enumerate software across the fleet and create a central software inventory. (Kolide does this for you)
Write scripts to pull down and parse vulnerability data feeds like the National Vulnerability Database.
Marry the data between the feed and the inventory to produce vulnerabilities.
Filter, and prioritize vulnerabilities based on CVSS score or other criteria.
Create an alerting/notification capability to drive vulnerability remediation.
I call this a top-down approach because it starts from a list of all known vulnerabilities and then works downward toward applying them to devices in an organization’s fleet.
On the surface, this appears to be an approach that should reduce the risk of serious compromise when done continuously. But does it help in practice?
As we saw in the study above, it turns out the answer is no. Follow this approach, and you will be quickly inundated with an enormous list of low-quality and non-actionable vulnerabilities. Soon, alert fatigue will set in, and the entire program is put at risk.
At Kolide, this topic isn’t just a curiosity; it’s essential learning. Our customers rely on end-users to quickly remediate major device compliance and security problems. We know from experience that end-user-driven remediation is only possible when you ensure the issues you send to employees are important, relevant, and actionable.
This article will explore why this top-down vulnerability management approach is not suited for organizations that want to remediate vulnerabilities. From there, we will reframe our perspective to how to best reason about vulnerabilities so that they can be solved directly by an untapped resource, the organization’s employees. By doing this, we will accomplish our goals of meaningfully reducing the risk of compromise due to lingering vulnerabilities.
Classic Vulnerability Management Does Not Yield Actionable Remediation
As security practitioners, we are forced to deal with the dramatic imbalance of effort exerted by defenders and attackers. This imbalance commonly referred to as the defender’s dilemma states that to thwart a bad actor, we must consider and successfully detect and defend against all known attacks. On the other hand, the bad actor just needs to find a single hole in that defense to win. This imbalance can cause us as defenders to slip into mindsets that seem rational but, in practice, produce outcomes that give attackers an even greater attack surface.
When defender-dilemma thinking is applied to vulnerability management, you get the classic top-down strategy outlined above. This strategy is designed to send the maximum amount of information to a small team of expert human operators who are expected to triage it and drive remediation. Unfortunately, this approach only works well if the following is true:
An operator can quickly review all possible use-cases of any device.
All aspects of any device from the operating system, to the software to the configuration, can be managed remotely and in a scalable way.
There is always a safe way to remediate the vulnerability (or mitigate the risk).
For most situations encountered, these properties are a fairy tale. It’s pretty standard for vulnerability management software to enumerate big flashing red lists of vulnerabilities that:
- have no vendor supported remediation path,
- relate to software that is not important or even used,
- overstate their applicability and their severity,
- will be fixed automatically without any intervention, or
- are just straight-up false positives.
While these problems afflict both servers and endpoints, it is the end-user-driven endpoints that are a terrible fit. To compensate, IT teams do precisely the wrong thing; they force the endpoints to change to best suit the broken vulnerability management process. For end-user-driven devices, this means maximizing the amount of remote management IT does on the device and minimizing the management tasks typically done by an end-user. Unfortunately, since end-user devices are multi-purpose (and those purposes cannot be fully known in advance), it’s nearly impossible for a skilled operator to triage vulnerabilities correctly. This creates a negative feedback loop where the operator will seek more data and more control over these endpoints.
Counterintuitively, this just makes the problem worse. The data needed by the IT team to make good decisions on behalf of the user starts to feel like dystopian-level surveillance. End-users begin to notice the performance and productivity impacts of endpoint management software. It’s not too long before an employee either works around it or starts using personal devices instead. When this ultimately happens, instead of reducing risk, you’ve eliminated your ability to enumerate it. On top of end-users being upset, you’ve created immeasurable and unlimited risk.
An End-User Focused Approach to Vulnerability Management
When we constrain our thinking by hyper-focusing on the defender’s dilemma, we let perfect be the enemy of good. This makes us blind to novel solutions that can significantly reduce (but not eliminate) the likelihood of a device becoming compromised.
One of those novel solutions is to enlist the help of the end-users directly and have them remediate serious vulnerabilities for us. As we wrote in Honest Security:
End-users can make rational and informed decisions about security risks when educated and honestly motivated.
To apply the values of Honest Security to vulnerability remediation, we need to devise a system optimized for our end-users. This means:
Encouraging preventative measures and behaviors (like keeping the OS and apps up-to-date) in favor of reporting individual vulnerabilities.
Ensuring issues reported to end-users are always accurate over providing them with an exhaustive but potentially flawed list of vulnerable software.
Preferring waiting for vendor-supported remediation to be available over the speed of reporting.
For certain apps, ignoring all but the highest risk and impact vulnerabilities.
This approach does not give you a theoretically perfect vulnerability remediation capability. That’s ok; we aren’t looking for perfect. Instead, we get an imperfect yet highly effective new tool to remediate incredibly nuanced vulnerabilities against apps where traditional automation cannot work. That is a significant upgrade from classic top-down vulnerability management.
How Kolide Applies These Principles to Checks
In the Kolide product, our checks feature allows IT administrators to verify that their devices are meeting specific requirements. For instance, Kolide ships with a check to ensure Google Chrome is always up-to-date.
In addition, Kolide also deploys checks to look for known violations of IT policy or high-impact security risks. This can include:
- Evil Applications (e.g. Malicious Browser Extensions)
- Misappropriated Sensitive Data or Credentials (e.g. Incorrectly stored 2FA Backup codes)
- Specific High-Impact Vulnerabilities
When a highly publicized vulnerability hits the news, customers will frequently ask us if we will build a check that detects it. With the end-user focus we advocate for above, we approach these decisions by answering the following questions:
Does this vulnerability result in remote code execution with minimal or no user interaction?
Is it unlikely the vulnerable software will update itself within a reasonable time frame without end-user or IT intervention?
Is there a straightforward vendor-provided mitigation available?
Is the likelihood of this same vulnerable component having a similar vulnerability in the next 90 days low?
If the answers to all of the above are a resounding yes, then it meets the criteria for end-user remediation, and therefore, it makes sense for us to ship a new check.
To demonstrate why these questions matter, let’s work through an example where we created such a check. Specifically, let’s talk about CVE-2019-9535, a vulnerability in popular terminal software iTerm2. To summarize, this vulnerability allows an attacker to craft specific output that, when viewed in the terminal, could cause the software to execute arbitrary commands. Now that we understand the nature of the vulnerability let’s walk through the checklist above.
Does this vulnerability result in remote code execution with minimal or no user interaction?
Yes. According to the report, during the ordinary course of using the app, a user can be easily tricked into running the exploit which can be leveraged to compromise the integrity of their device completely.
If this vulnerability didn’t result in an RCE, and simply crashed a device, it wouldn’t be worth fatiguing the user with a notification about this vulnerability.
Is it unlikely the vulnerable software will update itself within a reasonable time frame without end-user or IT intervention?
Yes. iTerm2 is not an evergreen app (more on this later), and while it does prompt users when an update is available, these updates can be easily skipped by users. This means we cannot even be reasonably sure that all vulnerable versions running in our environment will eventually become patched.
On the other hand, if this app was evergreen and the likelihood of probability within 30 days was low, it wouldn’t be worth fatiguing the user with a notification about this vulnerability.
Is there a clear vendor-provided mitigation available?
Yes. Simply following the update prompts immediately resolves the vulnerability. An end-user will have no trouble mitigating the risk, and we should have no problem writing step-by-step instructions that anyone familiar with the app can follow.
Why does this matter? It’s typical for severe vulnerabilities to be sometimes reported days or even weeks before a vendor can develop a mitigation or a patch. Sometimes the vendor-supported solutions never arrive. We must wait for the most user-friendly solution to become available so that we can drive the maximum impact through end-user notifications. Fatiguing the end-user with issues they cannot fix will simply train them to ignore the ones they can.
Is the likelihood of this same vulnerable component having a similar vulnerability in the next 90 days low?
Yes. While we can never perfectly predict the future, iTerm2 historically has not had many vulnerabilities, and it is unlikely to have another with the a similar severity in the next three months.
This is important; we do not want to fatigue end-users with a deluge of issues for the same application (especially when they just fixed it). If we think another vulnerability will be reported soon, we may either want to wait a few weeks to see how the situation develops or, if the app is essential, add it to a list of apps we ask users to keep up-to-date.
As you can see by the above example, we are doing everything to ensure we don’t inundate an end-user with too many low or medium priority alerts. We only want to contact them about serious problems and only when we can provide a clear path to remediation.
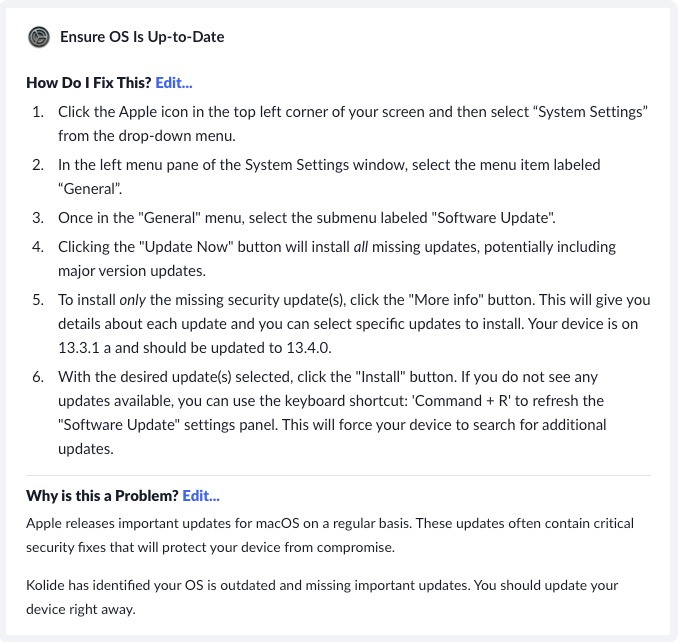
Here is an example of a message we may send to an end-user:
While the above rubric can be applied to most apps, popular evergreen apps like web browsers change the calculus significantly. Let’s discuss.
What About Evergreen Apps?
Many of our most important apps manage their own update process outside of the operating system’s central software update. Apps that do this are often known as evergreen apps, and they can significantly complicate the vulnerability management remediation story.
What Are Evergreen Apps?
The term evergreen comes from botany. Unlike seasonal flora, evergreen plants will remain green the entire year. Outside of botany, the term is used by multiple specialties to refer to things that are both fresh and timeless. For instance, in journalism, an evergreen article can be published anytime because it doesn’t reference current events.
In the software world, the term refers to apps that automatically keep themselves up-to-date without the user needing to participate in the process actively. In theory, every time you launch the app, you are use the latest version. Modern web browsers are the canonical example of evergreen software, with Google popularizing the practice shortly after its Chrome Browser was released in 2008.
Evergreen apps have significant advantages over apps with different release and update strategies. Before the majority of the web browser industry became evergreen, developers would often be stuck supporting web browsers that were years old. Today, if a vendor ships a new release, web developers can expect that release to become the dominant version in less than a month.
As I write this blog post, I am currently running the following evergreen apps: Google Chrome, Slack, Discord, and VSCode. To be honest, I’m not even sure if that is all of them. The benefit of an evergreen app is that the auto-update process is seamless; as a user, I simply don’t think about it.
All evergreen apps automatically update, but not all auto-updating apps are evergreen
There is a subtle yet important difference between apps that automatically update and those that can be considered evergreen. That difference is user consent.
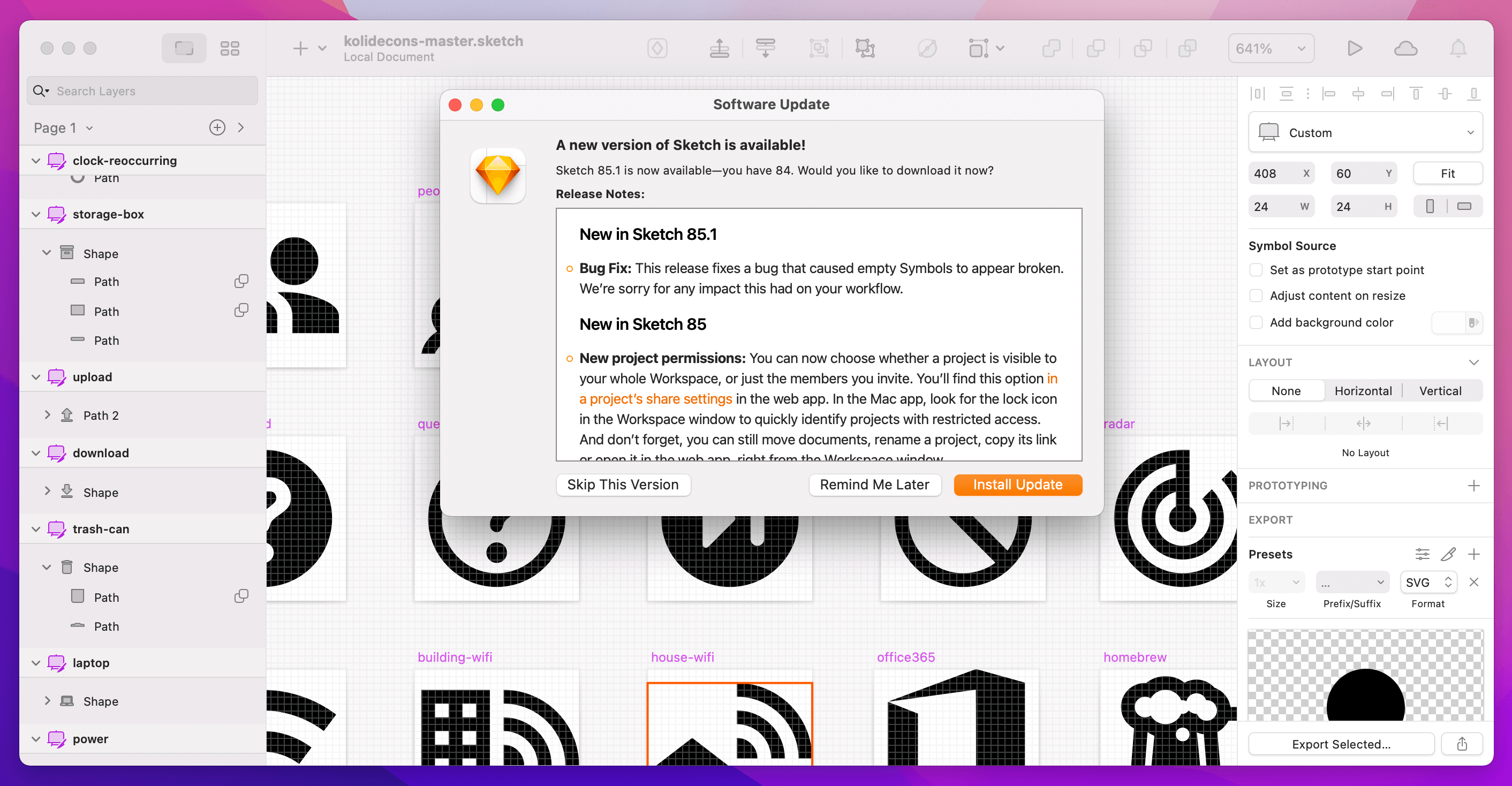
On macOS, you may be familiar with an automatic update process that looks like the following:
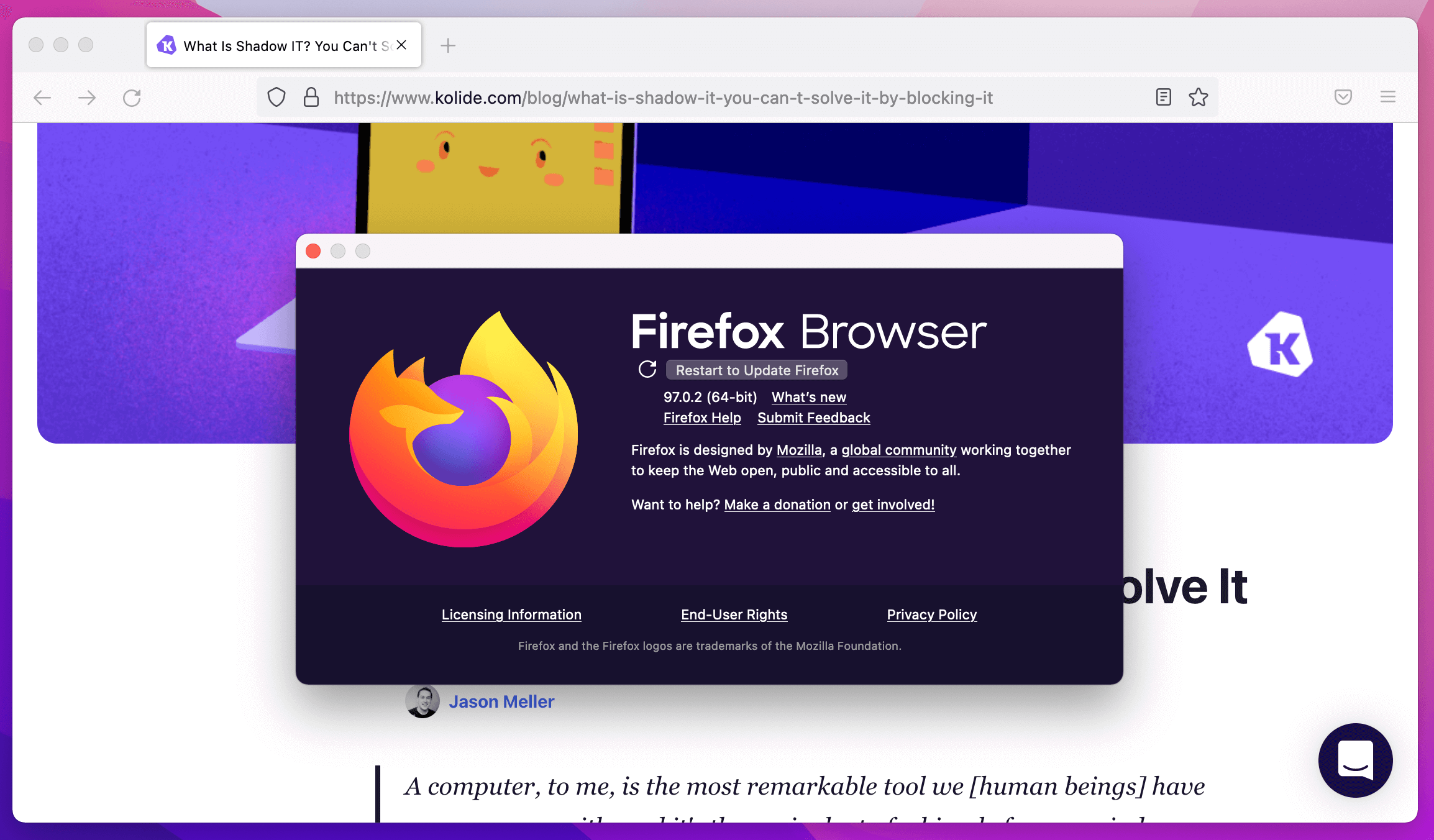
Compare that to the “About Firefox” pop-up when I launched an out-of-date copy of the app.
As you can see, with Sketch, the update process is almost like an advertisement doing everything it can to coax me into accepting the upgrade. This is because I can easily opt-out, especially if I fear that the new version could break my workflow.
With Firefox, I had to hunt to find the right screen to show any information about the version and the status of the update process. As a user, I am not meant to have any control over when this process occurs. The next time I restart Firefox, I will be on the latest version; there isn’t much I can do about that. This is the UX mostly closely associated with the term evergreen.
How to reason about vulnerability risk for evergreen apps
Remember the old philosophical question, “If a tree falls in the woods, but no one is around, does it make a sound?”. Well, with evergreen apps, we have a similar one to consider; if an app is vulnerable on disk but when launched is immediately updated to the non-vulnerable version, was it even vulnerable, to begin with?
At Kolide, we’ve learned through experience that the answer is, “it depends.” Let’s explore what important information we need to know the answer definitively.
The term evergreen isn’t descriptive enough for us to know how to approach building an acceptable vulnerability management strategy. We need to understand the probability of an exploit successfully running against a vulnerable evergreen app before it has a chance to upgrade itself.
To do that, We need more data about the app itself, the device that’s running it, and even the person who is regularly using that device. We can split this into two simple criteria.
Criteria #1: Is there a low-friction way to activate exploit?
For example, let’s take an attacker attempting to leverage an RCE-style vulnerability. This attacker will likely take a two-step approach: build a reliable exploit and then find a reliable way to get their victims to trigger it. Knowing how likely a victim is to trigger the exploit is vital information different for each device and end-user you are considering.
To enumerate this trigger risk, we often think about the following (ordered by severity):
Can the attacker trigger the exploit via a communication channel that pushes untrusted content to an end-user without their consent? (e.g. email, SMS, iMessage, etc.)
Can the attacker craft a malicious URL that causes the app to launch and immediately load the exploit?
Can the attacker craft a malicious file that causes the app to immediately load the exploit when opened?
Is the exploit so ubiquitously distributed that a user is likely to encounter the malicious payload through the normal course of their duties?
If we can answer in the affirmative to at least two of the three criteria above, then yes, low-friction activation is a threat.
Criteria #2: After launch, how quick in-practice does the app update?
When an update is released, evergreen apps are supposed to apply the update quickly. Unfortunately, this isn’t always the case. Not all apps poll for updates as frequently as you’d expect, and if the update process isn’t working correctly, an important update may never be applied. An obvious tell-tale sign is when you see an evergreen app running, but with a very old version.
The real devils can be found in the weird nuances around how an evergreen app updates. More specifically, after the update, can multiple versions of the app exist simultaneously?
There are two main evergreen update strategies, each with slightly different risks:
Seamless full update
This is the best strategy. After the update is downloaded and applied to the app in the background, the app restarts without any user interaction.
User action required
The worst strategy. Even after the update is downloaded and applied to the app in the background, the old code still runs until the user takes action (like entirely restarting the app).
Three approaches to evergreen vulnerability management
You want to pick one of the following vulnerability management strategies for each Evergreen app based on the criteria above.
Strategy #1: Ensure app is always up-to-date
In this strategy, we inform the user every time the app is out of date, within a grace period. A good example is the Kolide Chrome check.
This strategy is a good fit for common, regularly used apps that receive a continuous stream of security updates. Kolide chooses this for web-browsers and other apps with regular exposure to untrusted user-generated content (webpages).
In this strategy, the key to minimizing fatigue is only to generate an issue if we detect the app is in-use and out of date, unless there is a pathway to activate the exploit through opening an arbitrary file or via a link.
Strategy #2: Ensure app has the latest security-related update applied
This strategy is similar to #1, but instead of requiring all updates to be applied, we need to understand the release announcement and its security impact before asking a user to performing the upgrade.
Strategy #3: Ensure app evergreen system is working
This strategy detects that an app launched regularly is significantly out of date from the latest version. This is a good indicator that the app’s automatic update is damaged or has been disabled intentionally by an advanced user.
This is a good strategy for apps with similar exposure to a web browser but not the same amount of vulnerabilities (where nearly every minor update includes a security fix). Slack is an excellent example of this in action. It’s an app that really should always be up-to-date. If it isn’t, it’s a great indicator that something has gone wrong, which could result in a vulnerability being exploited, or even the app functioning poorly in the future.
Pulling It All Together
As we’ve learned above, we need to let go of any preconceived notions of what makes an effective vulnerability management program. That will open our minds to novel ideas that allow us to make real headway on user-driven endpoints.
The key is to distill down the use-cases that end-users can solve on their own and aggressively use tools that allow you to effectively communicate with them at scale to enable them to solve these problems on their own.
If the issues we ask our users to fix don’t feel important, are wrong, or aren’t actionable, we will lose their trust. When that happens, we’ve lost one of the most effective resources we have to solve challenging and nuanced security issues at scale.
If you are interested in learning more about end-user-driven remediation and the philosophy behind it, I encourage you to read Honest Security. If you want to get started with a turn-key product built on top of these principles, you should check out Kolide.